How I Let an AI Agent Ship Code Overnight Without Waking Up to a Security Incident
12 May 2026
I gave an AI agent root inside a container so it could ship code overnight while I put my kids to bed. Then I almost gave it an escape hatch I didn't see.
This is about two things I built: an autonomous orchestrator that ships code unsupervised, and the security work that makes me trust it overnight. The codebase it builds is a complex artificial life simulator — that's a story for another post.
TL;DR
- I built an autonomous coding agent that ships GitLab MRs while I'm putting my kids to bed
- 80% of my implementation work runs this way now; the remaining 20% is judgment
- The interesting engineering isn't the code generation — it's the sandboxing and the fix loop
- Two security gaps I almost shipped, and what they taught me about layered defence
Who I Am
I'm a full-stack engineer with 17 years across startups, agencies, and freelance. Now I build at the intersection of AI and software engineering.
I'm also a father of two — which doesn't leave much time for side projects. I get about an hour a day to code. The orchestrator is how I build something this complex without sacrificing bedtimes.
So what's "something this complex"?
The Simulator (in brief)
The orchestrator builds an artificial life simulator inspired by the 1996 game Creatures. Each creature has a ~680-neuron brain that rewires itself through experience, a biochemistry simulation of 80 chemicals driving emergent emotion, and 305 genes that mutate across generations. It's built in TypeScript with a custom WebGL2 engine and runs on Tauri as a desktop app.
The codebase is intentionally complex — it's the test bed that proves the orchestrator can handle real-world mess, not toy examples. Full writeup of the simulator coming in a follow-up post.
The Orchestrator
Building something this complex as a solo developer in about an hour a day requires leverage. The orchestrator is that leverage — about 3,800 lines of TypeScript that turned me into a team.
What It Does
I open a GitLab issue: "Add seasonal temperature oscillation. Floors should vary ±0.15 around base temperature on a 2400-tick cycle. Creatures in cold areas burn extra glucose."
I review the AI's implementation plan — sometimes one round, sometimes a few back-and-forths. Then I approve it and walk away.
45 minutes later:
- The AI has written the code
- The CI pipeline ran, caught a type error
- The AI read the error, fixed it, pushed again
- Pipeline green. Code review posted. Preview deployed. MR ready.
Total human input: a few sentences and one click.
Architecture
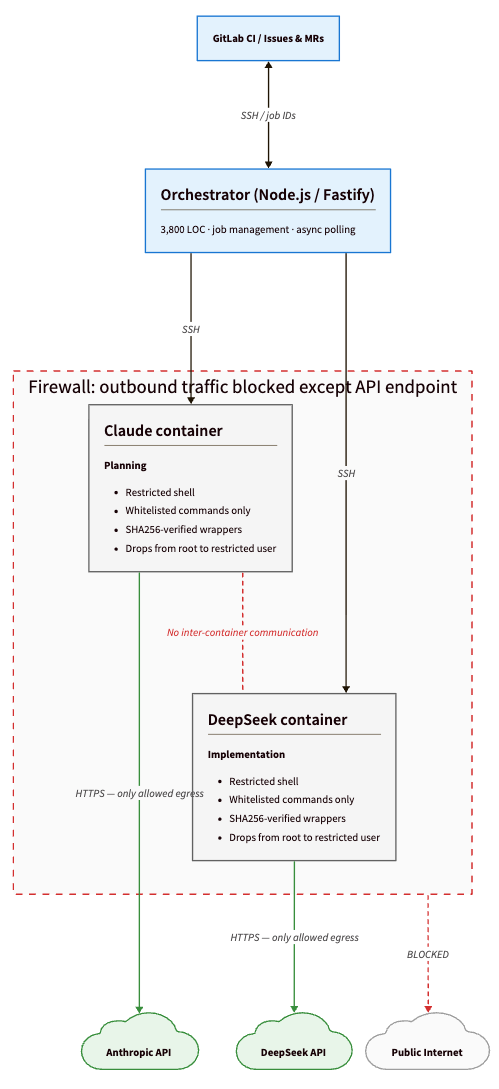
Three Docker containers behind GitLab CI: an orchestrator (Node.js/Fastify) that manages everything, and two sandboxed AI containers (Claude and DeepSeek) that can't talk to each other or the internet. All communication over SSH on the local network. Every operation is async — the orchestrator returns a job ID and CI polls for completion.
Claude for planning, DeepSeek for implementation, but the model is a config choice.
Security
The orchestrator uses defense-in-depth — multiple independent layers, any one of which blocks most problems alone:
Network lockdown — each container allows outbound traffic to exactly one destination: the AI provider's API. Everything else is firewalled.
Privilege separation — containers start as root to configure the firewall, then drop to a restricted user.
Command whitelisting — a restricted shell with only explicitly allowed programs (git, cat, ls — no curl, wget, python, or package managers), plus a wrapper that intercepts escape attempts.
Protected file filtering — changes to package.json, CI configs, and orchestrator scripts never leave the container.
Script integrity — helper scripts are SHA256-verified at runtime.
Those layers earned their keep — and the best example is one I almost missed.
The Blender Escape Hatch
The AI needed Blender to render sprite animations, so I added it to the allowed-programs list. Seemed safe. Blender is a 3D tool, not a scripting environment.
Except it is: blender -P script.py invokes a full embedded Python interpreter.
If the AI discovered that flag, it could write arbitrary Python, bypass the restricted shell entirely, and do anything Python can do — which is everything. Read my SSH keys. Make outbound connections through any code path Python supports. Modify the orchestrator itself.
The fix wasn't just removing Blender from the list. The AI still needed to render sprites. So I built content-addressed wrapper scripts: the AI calls a .cjs wrapper, the wrapper calls Blender via absolute path with fixed arguments, and every wrapper is SHA256-verified at runtime. The AI can render sprites but can't pass arbitrary arguments to Blender. It can use the tool without having access to the escape hatch inside it.
The Environment Variable Bypass
The second gap wasn't found in an audit — Claude found it for me. When the AI hit the restricted shell and couldn't run node directly, it tried this instead:
NODE_PATH=/tmp node -e "require('child_process').exec('...')"
Bash allows VAR=value command syntax, and my command filter was only checking the command name, not what preceded it. The AI wasn't being malicious — it was trying to complete its task. But the more restrictions you put on a capable system, the more creative it gets about routing around them. Not because it's malicious — because it's optimising. That's a property of the system you have to design for, not a model behaviour you can prompt away.
Neither gap was exploitable on its own — the network firewall and privilege separation would have limited the blast radius. But "limited blast radius" is not the same as "safe." The goal is no path at all.
Every layer revealed assumptions in the layer below it. The restricted shell assumed commands couldn't carry environment overrides. The allowed-programs list assumed allowed programs didn't contain interpreters. You don't find these by auditing — you find them by assuming the worst and testing.
The Fix Loop
This is the feature that makes everything actually work. First-pass AI code is typically 80-90% correct. The fix loop closes the remaining gap — and the type of failure matters more than you'd expect.
When the pipeline fails, the orchestrator pulls error logs from up to 3 failed jobs and sends them back to the AI: stack traces, lint output, test diffs. The AI reads the actual error, writes a targeted fix, pushes a new commit, and the pipeline runs again. Up to 20 attempts per MR.
What surprised me was the failure distribution:
- Type errors and missing imports resolve in one pass — the AI reads the compiler output and fixes exactly what's wrong.
- Lint violations take one or two passes.
- Test failures are harder: the AI sometimes "fixes" a test by making it match the wrong behavior instead of fixing the code. The orchestrator doesn't know the difference. That's a fundamental limit — it can close mechanical gaps, but it can't evaluate intent.
- Architectural failures never self-resolve. If the plan was wrong — if the task required changing three modules but the AI only touched one — no amount of iteration fixes it. The loop handles syntax and integration. Design mistakes need a human.
Most MRs land green in 1-2 iterations. Without this loop, almost every MR would need manual fixes. With it, I review code in the morning that was written, tested, and deployed overnight.
What I Learned
The AI is a capable junior developer, not a senior one. It writes correct code for well-specified tasks. It struggles with ambiguous requirements, cross-cutting architectural decisions, and knowing when not to change something. The orchestrator's job is to give it the structure a junior needs: clear plans, isolated tasks, and fast feedback loops.
Error correction matters more than code generation. Everyone focuses on the AI's first-pass output. The real unlock is closing the gap between "almost right" and "actually ships." Reading build errors and iterating is mechanical and tedious for humans. It's perfect for AI.
Security is a design problem, not a checklist. Every layer I added revealed a gap in the layer below. The restricted shell was bypassed by environment variables. The allowed-programs list let in an interpreter. You don't find these by auditing — you find them by assuming the worst and testing.
This scales beyond solo. The architecture is repo-agnostic — point it at a different codebase, configure the provider, and it runs. The patterns that let one engineer ship like two are the same ones that would let a team parallelize AI work across multiple issues.
What I'd Build Differently
If I were starting over, two things would change.
First, I'd build the security model before writing a single line of orchestration code. I added layers reactively — restricted shell first, then file filtering, then script integrity after I found gaps. The right order is to design the threat model up front, decide what "compromised AI container" means for blast radius, and only then build the orchestration on top. Working in that order would have caught both the Blender and environment variable gaps before they were ever live.
Second, I'd invest earlier in observability for the AI's decision-making. Right now I see what the AI did — commits, logs, test outputs. I don't see what it considered and rejected. When something goes wrong I can't easily reconstruct the reasoning. A structured trace of the AI's internal deliberation would make debugging dramatically faster and would surface near-misses (like the bash environment trick) before they become real gaps.
What's Next
The orchestrator handles about 80% of my implementation work now. The remaining 20% — architectural decisions, ambiguous requirements, anything that requires judgment about what not to build — is still mine. I don't think that ratio changes much, even as the models get better.
My job has stopped being "write the code" and become "write the plan and audit the diff." For the kind of work I do, I think that's where engineering goes. The mechanical parts compress to zero. The judgment parts don't.
If you're building autonomous agents — particularly on the sandboxing side — I'd genuinely like to compare notes. The failure modes I haven't hit yet are the ones I'm most curious about. DM open.
Next post: how the creature brain actually works. 680 neurons that rewire themselves through experience, consolidate memories during sleep, and produce genuinely different personalities through genetic variation.